

















The MONSTRO name has some history in the RED ecosystem, having been famously teased by none other than Jim Jannard himself, back in 2008, as a possible upgrade for the original Mysterium sensor in the RED ONE. That sensor never materialized, but the MONSTRO name found a home in the WEAPON MONSTRO 8K VV, released in October of 2017. MONSTRO is unique in the growing landscape of RED cameras because it incorporates their HELIUM sensor technology while keeping the same pixel size, or photosite area, as its DRAGON ancestor. The upshot is that those who owned or, more likely, were in line for the original full format DRAGON-based 8K sensor won't need to make any adjustments to use the new sensor for their projects – MONSTRO's dimensions, resolution, and pixel size match the earlier sensor.
So, to paraphrase Jerry Seinfeld, what's the deal with all these 8K cameras? Other than the stereotypically American desire for more, what is 8K good for? From a spatial resolution point of view, 8K provides the same ability to zoom in, re-frame, and look around inside of a frame in order to create multiple shots, or camera "moves", within a single overall frame. Many of us are used to doing this with 4K/UHD footage when finishing in HD. Now that the standard deliverable is shifting from HD to UHD throughout the industry, it stands to reason we want this same flexibility, which is something you don't get when shooting 4K at 1:1.
Beyond that, though, what other advantages does 8K really bring, other than, as reviewers like to say, "gobs and gobs of resolution." What does all this resolution really get us? If you're on the north side of 40, like me, you may find that your personal close focus distance seems to move out by an inch or two every year, a phenomenon called presbyopia (age-related farsightedness caused by a loss of elasticity in your eyes' lenses). In other words, at comfortable viewing distances, I can rarely, if ever, discern individual image pixels on a modestly sized HD screen. At 4K, I'm pretty sure in order to be close enough to see the benefit of the increased resolution in anything other than text or sharp-edged graphics, I would be near my personal "minimum object distance." Even for those with perfect vision, the equation of screen size and viewing distance doesn't make 4K or UHD viewing a necessity (at least in most New York City apartments). But, extra resolution is always nice to have, especially if you like to sit close or use a projector or other very large screen.
And, there are other nice things about current-generation 4K TVs, such as WCG (Wide Color Gamut) and HDR (High Dynamic Range) that bring image quality improvements that are visible from any distance. So, if we can agree that the problem of being able to discern individual pixels was solved, for all intents and purposes, with the move to HD in the middle "aughts", what is all this extra resolution really for? One answer may surprise some: better color.
"Wait a second," I hear you saying, "spatial resolution is completely orthogonal to color!" While this is strictly true—and kudos, by the way, on using 'orthogonal' in a sentence—the fact is that single-sensor camera systems are at a bit of a disadvantage vs. their 3CCD antecedants when it comes to capturing high resolution in the chroma domain. To understand why, we need to set the Way-Back machine to 1974 in Rochester, NY.

The above image is a page from Eastman Kodak Company Research Laboratories notebook #U203, written by Dr. Bryce Bayer on May 28, 1974. In this brief note, Dr. Bayer describes the fundamental approach used by virtually all camera image sensors today, that of the Primary Color Filter Array, to create color from an array of photo "detectors" (the light sensitive structures housed within photosites).
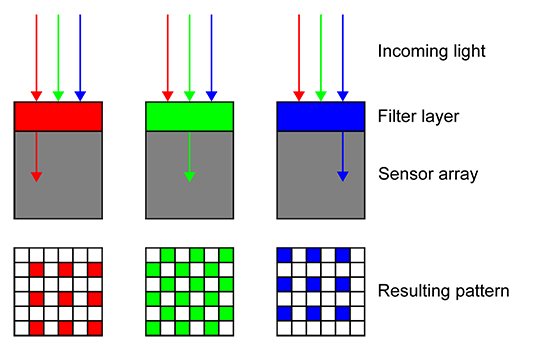
You may already know that camera sensors, whether they are charge-coupled devices (CCDs) or CMOS-based (complimentary metal oxide semiconductors), are inherently monochrome devices, in that they only record a value relative to the amount of light collected by each photosite. They are also, incidentally, analog devices, but that's a discussion for another time. For now, think of your camera's sensor as a dense grid of tiny light meters that register the intensity of light received at each square on the grid. In order to record color, variations on the approach outlined by Dr. Bayer above have been used since the advent of digital photography. The light hitting each photosite is filtered through a precisely engineered piece of transluscent colored gel in one of red, green or blue. These tiny chips of "fancy cellophane" cover all photosites on the sensor such that each one will see only a single primary color of light entering and record a value for, again, only that color. If computed directly, each resulting image pixel would contain a value only for a single color channel, with the others empty. Written in standard RGB triplet notation, a red filtered photosite, for example, recording a value of 50% (middle gray) would read '128,0,0'. An adjacent blue filtered pixel might read '0,128,0', and a nearby green pixel '0,0,128'.
So, if no individual photosite sees more than a single primary color of light, how do we get a full color RGB image from this approach? Let's discuss two approaches to decoding this mosaic of singly-colored pixels. The first, and original, approach (detailed in the patent that eventually resulted from Dr. Bayer's handwritten précis above) might seem obvious to some. It's to take a quad of adjacent pixels and record the red pixel's value for the red channel of a single pixel, blue for blue and green for green. The fourth component of a typical Bayer quad will be another green pixel, since the green part of the visible spectrum contains a proportionally higher amount of the brightness (luminance) and edge definition we perceive. This extra green information is accounted for during the decoding process, called de-mosaicing or de-Bayering, after Dr. Bayer, so as not to introduce an unnaturally green cast to the resulting image.
So, instead of four pixels with empty complementary color attributes (for the colors that they aren't), we end up with a single pixel that has full color information – but only a single pixel, where before we had four. This is what I refer to as the Bayer "tax." In order not to have to share, or otherwise invent, color values across adjacent pixels, in other words to achieve 4:4:4 color, where each color channel is sampled discretely, on a single chip sensor we must sacrifice 75% of our spatial resolution. There really isn't another way to get "full" or "true" color from a single chip sensor in real time using a Bayer pattern CFA (Color Filter Array). At 1:1 on the sensor, this information simply does not exist.
The second approach is, in a nutshell, guessing. Software engineers have a special word for this, interpolation, but it's basically a guess. It's a good guess, and one that's getting better all the time, but in the end it's still inventing values for pixels based on information from the pixels around it. For instance, if you'd like to guess the green channel value for a red pixel, you could look at all of the green pixels adjacent to it in every direction. Then, based on the values you find, split the difference to come up with a reasonable value to substitute for zero in the empty green channel of the pixel you're working on. Then, move on to the next, the next after that, and so on until all of the empty values are populated. Eventually you'd end up with a full color RGB image, but not one whose data was based on actual captured scene values for 2/3rds of the visual information. This sounds worse than it is, these interpolation algorithms have gotten very good over the past 20 years or so, but most experts still peg the overall resolution loss from this approach at between 30-40%. This could explain why we're seeing so many camera systems with ~6K sensors systems that oversample their sensors by roughly 1/3rd to create a 4K image.
What does all this have to do with 8K and RED's MONSTRO sensor? One of the big benefits of 8K resolution is that it allows us to perform this "brute force" ganging of color values and derive 4:4:4 color at UHD and DCI 4K deliverable resolutions. This approach was favored by many first- and second-generation digital cinema cameras from a wide range of manufacturers, and was often referred to as "4K for 2K." Sometimes, as automotive hot-rodders of the '50s and '60s used to say, "there's no substitute for cubic inches."
It should be said that color isn't the only image quality dimension that benefits from this approach of oversampling and downscaling. Below you'll see three thumbnails (photo credit: John Marchant), which you can click through to see full-size versions. The first is a frame captured at 2K and subsequently up-rezzed to 4K; the second is a frame of 4K captured and presented without resizing (aka 4K at "1:1"); last is a frame captured at 8K and downscaled to 4K. Most would agree that the upscaled 2K image is noticeably lower in quality. And while the 4K 1:1 image looks "fine" in isolation, when compared to the version sourced from 8K capture, it's easy to see the smoothness and definition, as well as increased color fidelity, that this approach brings.
|
|
|
|



